





Data Aggregation and Analysis
As the road network expands, so does the need to manage it better. Deployment and use of technologies and equipment that detect vehicles and capture other dynamic data can help. The capture, analysis and interpretation of this data lends itself to computer-based processing enabling the state of the network to be easily understood. The information that is produced by the data aggregation and analysis function is fundamental to managing road networks. (See Operational Activities)
The benefit of data aggregation and analysis increases with coverage of detectors - potentially extending into other regions that are the responsibility of other traffic authorities. Traffic management operations on travel corridors that include national roads, secondary routes and municipal routes, could benefit from traffic operators sharing sensor data, traffic reports and interpreted data.
There are many types of detector technologies which have different levels of accuracy, reliability, update rates and data content. The process of data aggregation and analysis provides filtering, error compensation, normalising and fusion with other data streams – to provide a picture of the status of a road link or the road network, which is useful for road management.
The purpose of data aggregation and analysis, otherwise known as Data Fusion is to estimate or predict traffic characteristics – such as current/future/mean vehicle speeds, vehicle classifications and their volume – as well as environmental information and other topics of interest to travellers.
A distributed network of detectors will provide a more accurate view of the state of the road network than is possible from information captured by a few detectors. Sophisticated analysis can:
- contribute to operational robustness - for example, by compensating for the failure of a detector
- increase the effective spatial coverage (by combining static measurements with probe vehicle measurements)
- increase reliability (since redundant data sources can help eliminate data conflict and errors)
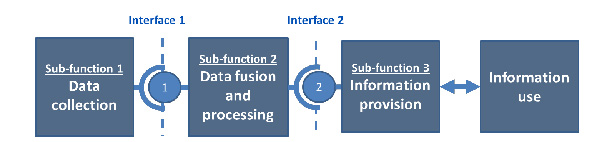
Data aggregation and analysis relates to Sub-function 2 of the Functional Architecture of a service – as shown below. There are many different approaches to aggregating real-time data in order to predict traffic conditions and provide journey time information. In general they include data validation and certification. The result is a measure of the Level of Service (LoS) of the monitored route. (See Monitoring and Evaluation)
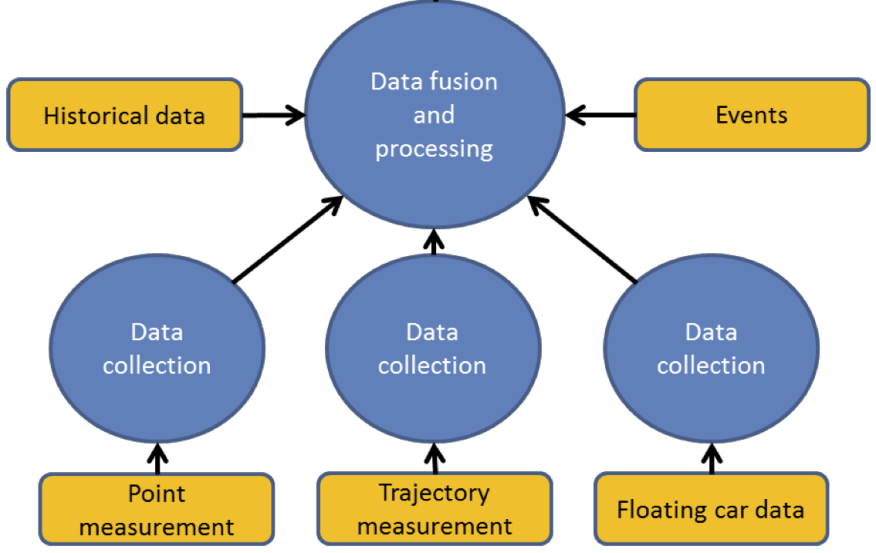
The most common traffic variables can be extracted by considering all types of detectors, fixed and mobile – and include:
- traffic volume count - the number of vehicles in a defined period of time - and vehicle classification (for example, counts estimated from loop detector data interpreted by roadside cameras)
- occupancy - the number of vehicles within a defined space
- speed - vehicle speed measured at discrete locations (by using, for example, inductive loops)
- average vehicle speed - measured by and calculated from mobile devices
Additional data may include historical traffic data, details of planned events, road closures and diversions.
TECHNOLOGIES DATA AND RESOURCES
Data aggregation and analysis depends on a network of measuring devices (static, mobile or a combination of both) and probe vehicle measurements. The process takes account of the characteristics of each type of detector to estimate the traffic state of the network.
Measured data may need to be pre-processed to correct for known errors, measurement bias and availability, and to update rates (data age) and coverage (small or large area). Typically, the methodologies used are:
- statistical - weighting and combining measured data using statistical measures and assumptions on distributions
- probabilistic / Bayesian - reasoning, assessing maximum likelihood and sophisticated ‘Kalman’ filters to estimate unknown variables from noisy data regardless of the underlying distribution of data
- fuzzy logic - estimation of traffic states assuming uncertainty, resulting in qualitative results
- expert systems - the application to measurements of stored knowledge and ‘genetic’ (iterative improvement) algorithms and rules
It may be necessary to progressively refine the measured data and to include additional sources – in order to improve its accuracy and trust in the data. Generally this process involves:
- converting the sensor data into known variables (such as volume, lane occupancy and vehicle speed)
- associating this data with road segments and compensating for any irregular or missing data
- initial interpretation, comparing the data set with other data sources (such as historic records or police reports)
- refining the impact assessment of the traffic condition using the measured data along with comparative data, data fusion and processing, to produce an estimate of likely duration – as summarised in the figure below
ADVICE TO PRACTITIONERS
The analysis of data collected from a distributed network of sensors can be extended beyond simple detection of vehicles to predict congestion, to refine the timings of signals in urban traffic control systems or to detect incidents. For example, a breakdown in the flow of traffic would be indicated by rapidly reduced flow rates and by an imbalance between detectors located before and after an incident.
The quality of traffic information based on a network of different sensor types and their configurations depends significantly on the quality of the data received from each measurement device or system.
Each measurement technology has its own characteristics, including its accuracy (how often its measurements are close to the truth) and its reliability and availability (the proportion of time that the device is working and able to provide data reliably):
the device might have an on-board internal clock – which may:
- be synchronised with other equipment or out of sync (because of a fault)
- have a time-offset compared with other devices or the system used for data fusion – (as with traffic signal control)
- other important characteristics will be the device’s ability to provide data continuously - or only from when a pre-programmed threshold has been reached, such as low visibility or floodwater on a road
The data aggregation process may need to fill in missing data, adjust for time offsets, and eliminate the effect of known faulty readings. The objective is to derive an accurate understanding of prevailing traffic conditions. At the same time the process needs to be sensitive to anomalies that might suggest an incident. For example, a CCTV camera can compensate for the failure of another if the cameras are placed so their coverage of the road network overlaps. Similarly, measurements based on probe vehicles can complement static detectors and extend the measurement coverage of static detectors.
In many regions, CCTV has provided the main source of traffic data to operators. As the CCTV coverage increases, the use of Automatic Incident Detection (AID) becomes a valuable tool for traffic officers - as a specialised form of data analysis that extends the capability of manual operators.
INSTITUTIONAL ISSUES
The process of data capture may include information that, when used by itself or when combined with other data, would be regarded as ‘personal information’ in some countries’ legal frameworks - raising issues of data protection and privacy. (See Legal and Regulatory Issues)
DATEX: a standard developed for information exchange between traffic management centres, traffic information centres and service providers, www.datex2.eu/
Keever, Shimizi et al.(2003) Data Fusion for Delivering Advanced Traveler Information Services, USDOT ITS Joint Program Office, Report # FHWA-OP-03-119, http://ntl.bts.gov/lib/jpodocs/repts_te/13837.html